This paper presents an interpretable multi-modal framework for screening potential plagiarism in GAN-generated abstract art. Because abstract works often resemble one another through palette, texture, rhythm, and massing rather than recognizable objects, single-metric or text-oriented plagiarism tools are insufficient. The proposed pipeline combines perceptual cues (MS-SSIM, color-distribution distances, Gram-matrix texture statistics, and edge topology), compositional cues (symmetry, balance, saliency spread, orientation entropy, and palette harmony), and semantic cues from CLIP and BLIP. Each channel is normalized, fused into a calibrated similarity score, and reported with uncertainty bounds and channel-level explanations. Using representative WikiArt-anchored cases and GAN-generated counterparts, the framework distinguishes probable derivation, stylistic influence, and independent creation more reliably than any isolated metric. The revised manuscript adds a consolidated related-work matrix, documented case provenance for A1–A5, illustrative output dossiers, and visual summaries of the comparative results. The method is intended as a transparent decision-support tool for scholarly, curatorial, and legal review rather than an automated adjudicator.
| Published in | American Journal of Art and Design (Volume 11, Issue 2) |
| DOI | 10.11648/j.ajad.20261102.11 |
| Page(s) | 39-53 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2026. Published by Science Publishing Group |
GAN-Generated Art, Abstract Painting, Similarity Fusion, Semantic Embeddings, Compositional Features, Intellectual Property
Line of work | Core technique | Typical dataset practice | Plagiarism target | Common pitfall | Future scope |
|---|---|---|---|---|---|
Style-based GANs (StyleGAN/StyleGAN2) | Latent mapping, style modulation, multiscale synthesis | WikiArt-derived abstract subsets or curated artist clusters | Near-derivation through palette, texture, and massing | Faithful distribution learning can preserve artist-specific priors too closely | Training-data provenance checks and memorization audits |
Creative Adversarial Networks (CAN) | Adversarial generation with style-deviation objective | Style-labeled art corpora such as WikiArt subsets | Influence masked as novelty | Deviation from style centroids does not rule out local source proximity | Joint novelty and provenance constraints |
Neural style transfer / Gram-based style models | Gram-matrix statistics and feature-space style transfer | WikiArt or paired style corpora | Surface borrowing, textural imitation | Captures texture well but under-represents layout and authorship context | Fuse with composition- and semantics-aware evidence |
Classical image plagiarism / forensics | Copy-move detection, robust hashing, near-duplicate retrieval | Image-forensics benchmarks and art image collections | Literal duplication or local patch reuse | Weak for abstract works with non-iconographic similarity | Art-specific benchmarks for abstract painting |
Vision-language retrieval | CLIP, BLIP, caption-image embedding alignment | Captioned art corpora, WikiArt-derived metadata sets | Semantic or stylistic echoes | Web-data bias, caption drift, and unstable explanations | Domain-adapted encoders with explanation checks |
Proposed fusion framework | Perceptual + compositional + semantic fusion with calibrated scoring | Verified representative cases linked to artwork records and GAN counterparts | Probable derivation vs. influence vs. independence | Small-sample calibration and threshold sensitivity | Larger audited benchmark sets and cross-institution validation |
1 Preprocess q once: |
2 resize_to_long_edge(q, 768); linear_rgb(q); |
Tornado Tango (Martin Disler, 1984) |
Untitled (Joan Mitchell, 1958) |
Untitled (Joan Mitchell, 1959) |
Untitled (Joan Mitchell, 1960) |
Untitled (Joan Mitchell, 1961) |
8 ms_ssim(q,r), |
9 palette_prox: = invert_emd(histHSV(q), histHSV(r)), |
10 chi2_HSV(q,r), jsd_HSV(q,r), |
11 gram_style_sim(q,r; multi-layer), |
12 skel_iou(edges(q),edges(r)), hausdorff_contour(q,r) |
13 } |
14 // Compositional metrics (layout, balance, rhythm, hierarchy) |
15 M_comp: = { |
16 symmetry_corr(q,r), balance_delta(q,r), |
17 flow_coherence_div(q,r), orient_entropy_div(q,r), |
18 saliency_emd(q,r), log_radial_slope_diff(q,r) |
19 } |
20 // Semantic metrics (style and concept) |
21 M_sem: = { |
22 clip_img_img(q,r), |
23 clip_img_text_avg(q, lexicon), clip_text_img_avg(r, lexicon), |
24 blip_caption_cos(q,r) |
25 } |
26 // Normalize and channel-aggregate |
27 Z_perc: = { (m - μ_m)/σ_m: m ∈ M_perc }; P: = mean(Z_perc) |
28 Z_comp: = { (m - μ_m)/σ_m: m ∈ M_comp }; C: = mean(Z_comp) |
29 Z_sem: = { (m - μ_m)/σ_m: m ∈ M_sem }; M: = mean(Z_sem) |
30 // Fraction-free fusion and decision variable |
31 z: = w_P·P + w_C·C + w_M·M + b |
32 SSS: = exp(- softplus(- z)) // softplus(u) = log(1 + exp(u)) |
33 // Store per-reference results |
34 save(j, SSS, P, C, M, contrib: = {w_P·P, w_C·C, w_M·M}, top_metrics: = top|Z|) |
35 end for |
36 // Set-level aggregation |
37 j*: = argmax_j SSS_j |
38 (SSS*, P*, C*, M*, contrib*, top_metrics*): = results_of(j*) |
39 // Final decision |
40 if SSS* ≥ τ then return FLAG, SSS*, (P*,C*,M*), contrib*, top_metrics* |
41 else return NOT_FLAG, SSS*, (P*,C*,M*), contrib*, top_metrics* |
Artwork ID | Original (Artist, Year) | GAN Output | Dataset | CLIP Cosine | BLIP Cosine | Interpretation |
|---|---|---|---|---|---|---|
A1 | Tornado Tango (Martin Disler, 1984) | StyleGAN2 | WikiArt | 0.88 | 0.86 | The semantics align closely and suggest probable plagiarism. |
A2 | Untitled (Joan Mitchell, 1958) | CAN | WikiArt | 0.62 | 0.65 | The semantics indicate influence without direct replication. |
A3 | Patrice (Joan Mitchell, 1974) | StyleGAN2 | WikiArt | 0.91 | 0.89 | The semantics are strongly aligned and point to probable plagiarism. |
A4 | Untitled (Joan Mitchell, 1960) | CAN | WikiArt | 0.55 | 0.58 | The semantics remain low and support independent creation. |
A5 | Untitled (Joan Mitchell, 1960) | StyleGAN2 | WikiArt | 0.77 | 0.74 | The semantics fall in an intermediate band that warrants caution. |
Artwork ID | Spatial Entropy Deviation | Centroid Alignment Deviation | Fractal Dimension Difference | Color Harmony Similarity | Interpretation |
|---|---|---|---|---|---|
A1 | 0.04 | 0.03 | 0.02 | 0.91 | The composition echoes the original with tight massing and tonal fit. |
A2 | 0.12 | 0.15 | 0.10 | 0.68 | The composition diverges despite surface palette echoes. |
A3 | 0.03 | 0.05 | 0.01 | 0.89 | The composition aligns at structural and harmonic levels. |
A4 | 0.20 | 0.18 | 0.15 | 0.55 | The composition departs materially across cues. |
A5 | 0.08 | 0.09 | 0.07 | 0.75 | The composition shows partial alignment short of identity. |
Artwork ID | Semantic Average (CLIP+BLIP) | Compositional Score | Multi-Modal Index | Plagiarism Assessment |
|---|---|---|---|---|
A1 | 0.87 | 0.90 | 0.885 | The joint evidence supports a finding of probable plagiarism. |
A2 | 0.635 | 0.68 | 0.657 | The joint evidence supports a reading of stylistic influence. |
A3 | 0.90 | 0.91 | 0.905 | The joint evidence supports a finding of probable plagiarism. |
A4 | 0.565 | 0.48 | 0.523 | The joint evidence supports independent creation. |
A5 | 0.755 | 0.78 | 0.767 | The joint evidence supports a cautious label of potential derivative. |
GAN | Generative Adversarial Network |
| [1] | Goodfellow, I. J. Generative adversarial networks. Communications of the ACM. 2020, 63(11), 139-144. |
| [2] | Karras, T., Laine, S., Aila, T. A style-based generator architecture for generative adversarial networks. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019, 4401-4410. Available from: |
| [3] | Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y. Generative adversarial nets. arXiv. 2014, arXiv:1406.2661. Available from: |
| [4] | Elgammal, A., Liu, B., Elhoseiny, M., Mazzone, M. CAN: Creative adversarial networks, generating "art" by learning about styles and deviating from style norms. Proceedings of the Eighth International Conference on Computational Creativity. 2017, 96-103. Available from: |
| [5] |
Tate. Abstract art. Available from:
https://www.tate.org.uk/art/art-terms/a/abstract-art (accessed 23 October 2025). |
| [6] |
The Museum of Modern Art. Abstraction. Available from:
https://www.moma.org/collection/terms/abstraction (accessed 23 October 2025). |
| [7] |
Tate. Appropriation. Available from:
https://www.tate.org.uk/art/art-terms/a/appropriation (accessed 23 October 2025). |
| [8] | Buskirk, M. The contingent object of contemporary art. Cambridge, MA: MIT Press; 2003, pp. 1-18. |
| [9] | Abd Warif, N. B., Wahab, A. W. A., Idris, M. Y. I., Salleh, R., Othman, F. Copy-move forgery detection: Survey, challenges and future directions. Journal of Network and Computer Applications. 2016, 75, 259-278. |
| [10] | Thyagharajan, K. K., Kumar, S. A. P. A review on near duplicate detection of images using computer vision techniques. arXiv. 2020, arXiv:2009.03224. Available from: |
| [11] | Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I. Learning transferable visual models from natural language supervision. Proceedings of the 38th International Conference on Machine Learning. 2021, 139, 8748-8763. Available from: |
| [12] | Li, J., Li, D., Xiong, C., Hoi, S. C. H. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. Proceedings of the 39th International Conference on Machine Learning. 2022, 162, 12888-12900. Available from: |
| [13] | Redies, C., Brachmann, A. Statistical image properties in large subsets of traditional art, bad art, and abstract art. Frontiers in Neuroscience. 2017, 11, 593. |
| [14] | Datta, R., Joshi, D., Li, J., Wang, J. Z. Studying aesthetics in photographic images using a computational approach. In: Leonardis, A., Bischof, H., Pinz, A. eds. Computer Vision - ECCV 2006. Berlin: Springer; 2006, pp. 288-301. |
| [15] |
U.S. Copyright Office. Works containing material generated by artificial intelligence. Available from:
https://www.copyright.gov/ai/ai_policy_guidance.pdf (accessed 23 October 2025). |
| [16] |
U.S. Copyright Office. Copyright and artificial intelligence, Part 3: Generative AI training. Available from:
https://www.copyright.gov/ai/ (accessed 23 October 2025). |
| [17] |
World Intellectual Property Organization. The WIPO conversation on intellectual property and frontier technologies. Available from:
https://www.wipo.int/about-ip/en/frontier_technologies/conversation.html (accessed 23 October 2025). |
| [18] | Redies, C. Combining universal beauty and cultural context in a model of aesthetic experience. Frontiers in Human Neuroscience. 2015, 9, 218. |
| [19] |
Gatys, L. A., Ecker, A. S., Bethge, M. Image style transfer using convolutional neural networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016, 2414-2423. Available from:
https://openaccess.thecvf.com/content_cvpr_2016/html/Gatys_Image_Style_Transfer_CVPR_2016_paper.html |
| [20] |
Ahmed, I. T., Hammad, B. T., Jamil, N. A comparative analysis of image copy-move forgery detection techniques. Indonesian Journal of Electrical Engineering and Computer Science. 2021, 22(2), 1177-1190. Available from:
https://ijeecs.iaescore.com/index.php/IJEECS/article/view/23881 |
| [21] | Wang, Z., Bovik, A. C., Sheikh, H. R., Simoncelli, E. P. Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing. 2004, 13(4), 600-612. |
| [22] | Rubner, Y., Tomasi, C., Guibas, L. J. The Earth Mover's Distance as a metric for image retrieval. International Journal of Computer Vision. 2000, 40(2), 99-121. |
| [23] | Johnson, C. R. Jr., Hendriks, E., Berezhnoy, I. J., Brevdo, E., Hughes, S. M., Daubechies, I., Li, J., Postma, E., Wang, J. Z. Image processing for artist identification: Computerized analysis of Vincent van Gogh's painting brushstrokes. IEEE Signal Processing Magazine. 2008, 25(4), 37-48. |
| [24] | Redies, C. A universal model of aesthetic perception based on the sensory coding of natural stimuli and art. Vision Research. 2017, 133, 130-144. |
| [25] | Hauagge, A. C. B., Snavely, N. Image matching using local symmetry features. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2012, 206-213. |
| [26] | Cohen-Or, D., Sorkine, O., Gal, R., Leyvand, T., Xu, Y.-Q. Color harmonization. ACM Transactions on Graphics. 2006, 25(3), 624-630. |
| [27] | Canny, J. A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1986, 8(6), 679-698. |
| [28] | Hou, X., Zhang, L. Saliency detection: A spectral residual approach. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2007, 1-8. |
| [29] | Wang, Z., Simoncelli, E. P., Bovik, A. C. Multiscale structural similarity for image quality assessment. Proceedings of the 37th Asilomar Conference on Signals, Systems and Computers. 2003, 1398-1402. |
| [30] | Lin, J. Divergence measures based on the Shannon entropy. IEEE Transactions on Information Theory. 1991, 37(1), 145-151. |
| [31] | Zhang, T. Y., Suen, C. Y. A fast parallel algorithm for thinning digital patterns. Communications of the ACM. 1984, 27(3), 236-239. |
| [32] | Huttenlocher, D. P., Klanderman, G. A., Rucklidge, W. J. Comparing images using the Hausdorff distance. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1993, 15(9), 850-863. |
| [33] | Bigun, J., Granlund, G. H. Optimal orientation detection of linear symmetry. Computer Vision, Graphics, and Image Processing. 1987, 37(1), 23-33. |
| [34] | Field, D. J. Relations between the statistics of natural images and the response properties of cortical cells. Journal of the Optical Society of America A. 1987, 4(12), 2379-2394. |
| [35] | Itten, J. The elements of color. New York, NY: Van Nostrand Reinhold; 1970, pp. 20-22. |
| [36] | Hastie, T., Tibshirani, R., Friedman, J. The elements of statistical learning: Data mining, inference, and prediction. 2nd ed. New York, NY: Springer; 2009, pp. 119-127. |
| [37] | Efron, B., Tibshirani, R. J. An introduction to the bootstrap. New York, NY: Chapman and Hall/CRC; 1993, pp. 160-186. |
| [38] |
WikiArt. Visual art encyclopedia. Available from:
https://www.wikiart.org/ (accessed 23 October 2025). |
| [39] | Gonzalez, R. C., Woods, R. E. Digital image processing. 4th ed. Hoboken, NJ: Pearson; 2018, pp. 857-861. |
| [40] | Zadrozny, B., Elkan, C. Transforming classifier scores into accurate multiclass probability estimates. Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2002, 694-699. |
| [41] | Cohen, J. A coefficient of agreement for nominal scales. Educational and Psychological Measurement. 1960, 20(1), 37-46. |
| [42] | Fleiss, J. L. Measuring nominal scale agreement among many raters. Psychological Bulletin. 1971, 76(5), 378-382. |
| [43] | Efron, B. Bootstrap methods: Another look at the jackknife. The Annals of Statistics. 1979, 7(1), 1-26. |
| [44] | Lipton, Z. C. The mythos of model interpretability. Communications of the ACM. 2018, 61(10), 36-43. |
| [45] | Doshi-Velez, F., Kim, B. Towards a rigorous science of interpretable machine learning. arXiv. 2017, arXiv:1702.08608. Available from: |
| [46] | Kendall, A., Gal, Y. What uncertainties do we need in Bayesian deep learning for computer vision? arXiv. 2017, arXiv:1703.04977. Available from: |
| [47] | Davis, J., Goadrich, M. The relationship between precision-recall and ROC curves. Proceedings of the 23rd International Conference on Machine Learning. 2006, 233-240. |
| [48] | Goodfellow, I., Bengio, Y., Courville, A. Deep learning. Cambridge, MA: MIT Press; 2016, pp. 505-531. |
| [49] | Fawcett, T. An introduction to ROC analysis. Pattern Recognition Letters. 2006, 27(8), 861-874. |
| [50] | Wachter, S., Mittelstadt, B., Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harvard Journal of Law and Technology. 2018, 31(2), 841-887. Available from: |
| [51] | Ben-David, S., Blitzer, J., Crammer, K., Pereira, F. A theory of learning from different domains. Machine Learning. 2010, 79(1-2), 151-175. |
| [52] |
International Organization for Standardization. ISO/IEC 27037:2012 Information technology - Security techniques - Guidelines for identification, collection, acquisition and preservation of digital evidence. Available from:
https://www.iso.org/standard/44381.html (accessed 23 October 2025). |
| [53] |
National Institute of Standards and Technology. Special Publication 800-92: Guide to computer security log management. Available from:
https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-92.pdf (accessed 23 October 2025). |
| [54] |
Internet Engineering Task Force. RFC 3161: Internet X.509 Public Key Infrastructure time-stamp protocol (TSP). Available from:
https://www.rfc-editor.org/rfc/rfc3161 (accessed 23 October 2025). |
APA Style
Choi, B. (2026). Plagiarism Detection in GAN-Generated Abstract Art: A Multi-Modal Semantic and Compositional Approach. American Journal of Art and Design, 11(2), 39-53. https://doi.org/10.11648/j.ajad.20261102.11
ACS Style
Choi, B. Plagiarism Detection in GAN-Generated Abstract Art: A Multi-Modal Semantic and Compositional Approach. Am. J. Art Des. 2026, 11(2), 39-53. doi: 10.11648/j.ajad.20261102.11
@article{10.11648/j.ajad.20261102.11,
author = {Byungkil Choi},
title = {Plagiarism Detection in GAN-Generated Abstract Art:
A Multi-Modal Semantic and Compositional Approach},
journal = {American Journal of Art and Design},
volume = {11},
number = {2},
pages = {39-53},
doi = {10.11648/j.ajad.20261102.11},
url = {https://doi.org/10.11648/j.ajad.20261102.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajad.20261102.11},
abstract = {This paper presents an interpretable multi-modal framework for screening potential plagiarism in GAN-generated abstract art. Because abstract works often resemble one another through palette, texture, rhythm, and massing rather than recognizable objects, single-metric or text-oriented plagiarism tools are insufficient. The proposed pipeline combines perceptual cues (MS-SSIM, color-distribution distances, Gram-matrix texture statistics, and edge topology), compositional cues (symmetry, balance, saliency spread, orientation entropy, and palette harmony), and semantic cues from CLIP and BLIP. Each channel is normalized, fused into a calibrated similarity score, and reported with uncertainty bounds and channel-level explanations. Using representative WikiArt-anchored cases and GAN-generated counterparts, the framework distinguishes probable derivation, stylistic influence, and independent creation more reliably than any isolated metric. The revised manuscript adds a consolidated related-work matrix, documented case provenance for A1–A5, illustrative output dossiers, and visual summaries of the comparative results. The method is intended as a transparent decision-support tool for scholarly, curatorial, and legal review rather than an automated adjudicator.},
year = {2026}
}
TY - JOUR T1 - Plagiarism Detection in GAN-Generated Abstract Art: A Multi-Modal Semantic and Compositional Approach AU - Byungkil Choi Y1 - 2026/04/13 PY - 2026 N1 - https://doi.org/10.11648/j.ajad.20261102.11 DO - 10.11648/j.ajad.20261102.11 T2 - American Journal of Art and Design JF - American Journal of Art and Design JO - American Journal of Art and Design SP - 39 EP - 53 PB - Science Publishing Group SN - 2578-7802 UR - https://doi.org/10.11648/j.ajad.20261102.11 AB - This paper presents an interpretable multi-modal framework for screening potential plagiarism in GAN-generated abstract art. Because abstract works often resemble one another through palette, texture, rhythm, and massing rather than recognizable objects, single-metric or text-oriented plagiarism tools are insufficient. The proposed pipeline combines perceptual cues (MS-SSIM, color-distribution distances, Gram-matrix texture statistics, and edge topology), compositional cues (symmetry, balance, saliency spread, orientation entropy, and palette harmony), and semantic cues from CLIP and BLIP. Each channel is normalized, fused into a calibrated similarity score, and reported with uncertainty bounds and channel-level explanations. Using representative WikiArt-anchored cases and GAN-generated counterparts, the framework distinguishes probable derivation, stylistic influence, and independent creation more reliably than any isolated metric. The revised manuscript adds a consolidated related-work matrix, documented case provenance for A1–A5, illustrative output dossiers, and visual summaries of the comparative results. The method is intended as a transparent decision-support tool for scholarly, curatorial, and legal review rather than an automated adjudicator. VL - 11 IS - 2 ER -
College of Art and Design, Wonkwang University, Iksan, Republic of Korea
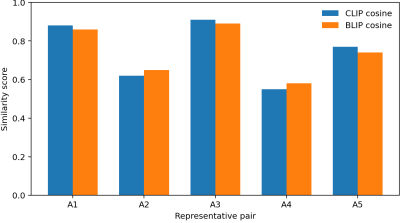
Figure 1. Visual comparison of CLIP and BLIP scores for Table 3.
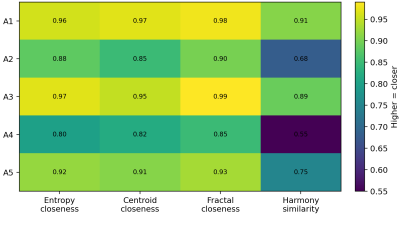
Figure 2. Heatmap summary of the compositional evidence reported in Table 4.
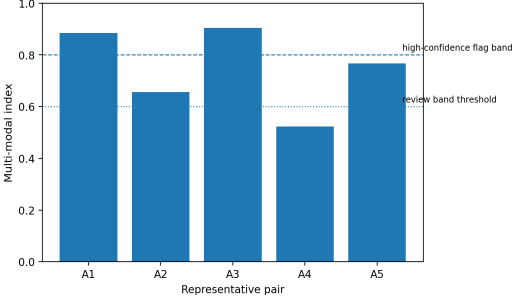
Figure 3. Multi-modal index derived from the comparative values in Table 5.

Figure 4. Example application dossier showing document, paragraph, and image outputs.

